Desktop Survival Guide
by Graham Williams
|
|
DATA MINING
Desktop Survival Guide by Graham Williams |
|
|||
|





|
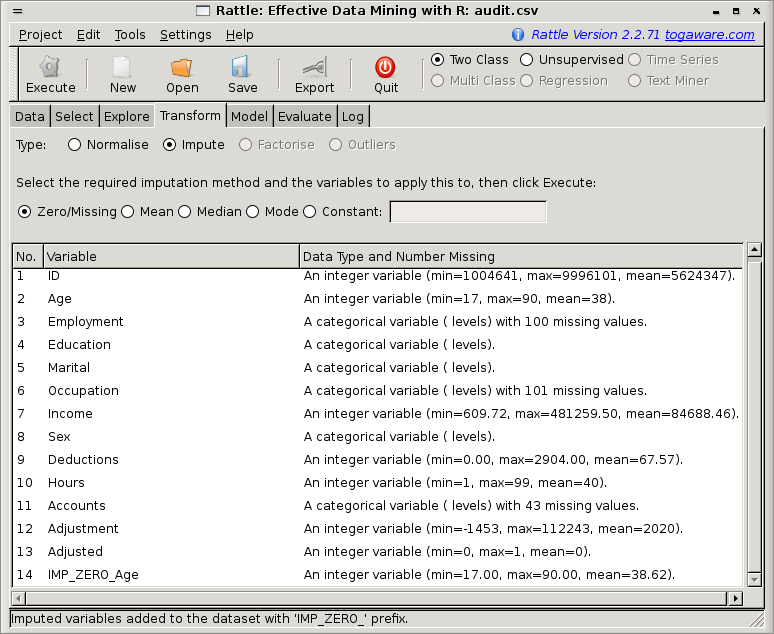
Imputation is the process of filling in the gaps (or missing values) in data. Often, data will contain missing values, and this can cause a problem for some modelling algorithms. For example, the random forest option silently removes any observation with any missing value! For datasets with a very large number of variables, and a reasonable number of missing values, this may well result in a small, unrepresentative dataset, or even no dataset at all!
There are many types of imputations available, only some of which are directly available in Rattle. We note thought that there is always discussion about whether imputation is a good idea or not. After all, we end up inventing data to suit the needs of the tool we are using. We won't discuss the pros and cons in much detail, but we provide some observations and concentrate on how we might impute values. Do be aware though that imputation can be problematic.
If the missing data pattern is monotonic, then imputation can be simplified. See () for details. Th pattern of missing values is also useful in suggesting which variables could be candidates for imputing the missing values of other variables. Refer to the Show Missing check button of the Summary option of the Explore tab for details
(see Section 6.1.6).
When Rattle performs an imputation it will store the results in a variable of the dataset which has the same name as the variable that is imputed, but prefixed with IMP_. Such variables, whether they are imputed by Rattle or already existed in the dataset loaded into Rattle (e.g., a dataset from SAS), will be treated as input variables, and the original variable marked to be ignored.