
Desktop Survival Guide
by Graham Williams
|
|
DATA MINING
Desktop Survival Guide by Graham Williams |
|
|||





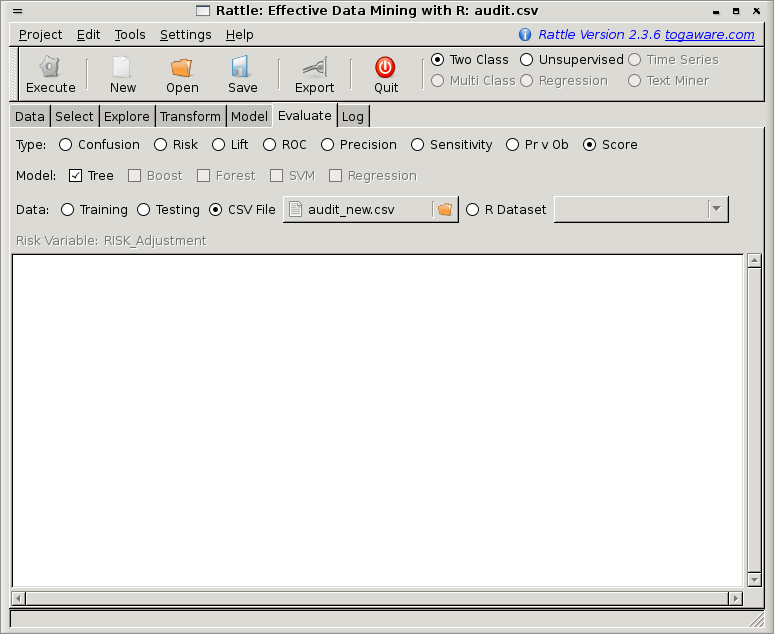
Often you will want to apply a model to a dataset to generate the scores for each entity in the dataset. Such scores may be useful for further exploration in other tools, of for actual deployment.
The Score radio button allows you to score (i.e., to generate probabilities for each entry in) a dataset. The specific dataset which is scored is that which is identified with the Data option. In the above example, the model will be used to score the Testing dataset. You can score the actual Training dataset, a dataset loaded from a CSV data file, or from a dataset already loaded into R.
Rattle will generate a CSV file containing the ``scores'' for the dataset. Each line of the CSV file will consist of a comma separated list of all of the variables that have been identified as Idents in the Variables tab, followed by the score itself. This score will be a number between 0 and 1.
Note the status bar in the sample screenshot has identified that the score file has been saved to the suitably named file. The file name is derived from name of the dataset (perhaps a source data csv filename or the name of an R data frame), whether it is a test or training dataset, the type of model and the type of score.
The output looks like:
ID,predict 98953270,0.104 12161980,NA 96316627,0.014 54464140,0.346 57742269,0.648 19307037,0.07 61179245,0.004 36044473,0.338 19156946,0.33 |