
This was originally shared as a Revolution Analytics Blog Post on 25th October 2016.
Programming is an art and a way we express ourselves. As we write our programs we should keep in mind that someone else is very likely to be reading it. We can facilitate the accessibility of our programs through a clear presentation of the messages we are sharing.
As data scientists we also practice this art of programming. Indeed even more so we aim to share the narrative of our discoveries through our living and breathing of data through programming over the data. Writing programs so that others understand why and how we analysed our data is crucial. Data science is so much more than simply building black box analyses and models and we should be seeking to expose and share the process and particularly the knowledge that is discovered from the data.
Style is important in making the code we share readily accessible. Dictating a style to others is a sensitive issue. We thrive on our freedom to innovate and to express ourselves how we want but we also need consistency in how we do that and a style guide supports that. A style guide also helps us journey through a new language, providing a foundation for developing, over time, our own style in that language.
Through a style guide we share the tips and tricks for communicating clearly through our programs. We communicate through the language — a language that also happens to be executable by a computer. In this language we follow precisely specified syntax to develop sentences, paragraphs, and whole stories. Whilst there is infinite leeway in how we express ourselves in any language we can share a common set of principles as our style guide.
Over the years styles developed for very many different languages have evolved together with the medium for interacting with computers. I have a style guide for R that presents my personal and current choices. This is the style guide I suggest (even require) for projects I lead.
I hope the guide might be useful to others. It augments the other R style guides out there by providing the rationale for my choices. Irrespective of whether specific style suggestions suit you or not, choose your own and use them consistently. Do focus on communicating with others in the first instance and secondarily on the execution of your code (though critical it is). Think of writing programs as writing narratives for others to read, to enjoy, to learn from and to build upon. It is a creative act to communicate well with our colleagues — be creative with style.
Hands On Data Science: Sharing R Code — With Style
The featured image comes from https://blog.codinghorror.com/new-programming-jargon/ where the concept of Egyptian Brackets is explained.
Graham @ Microsoft

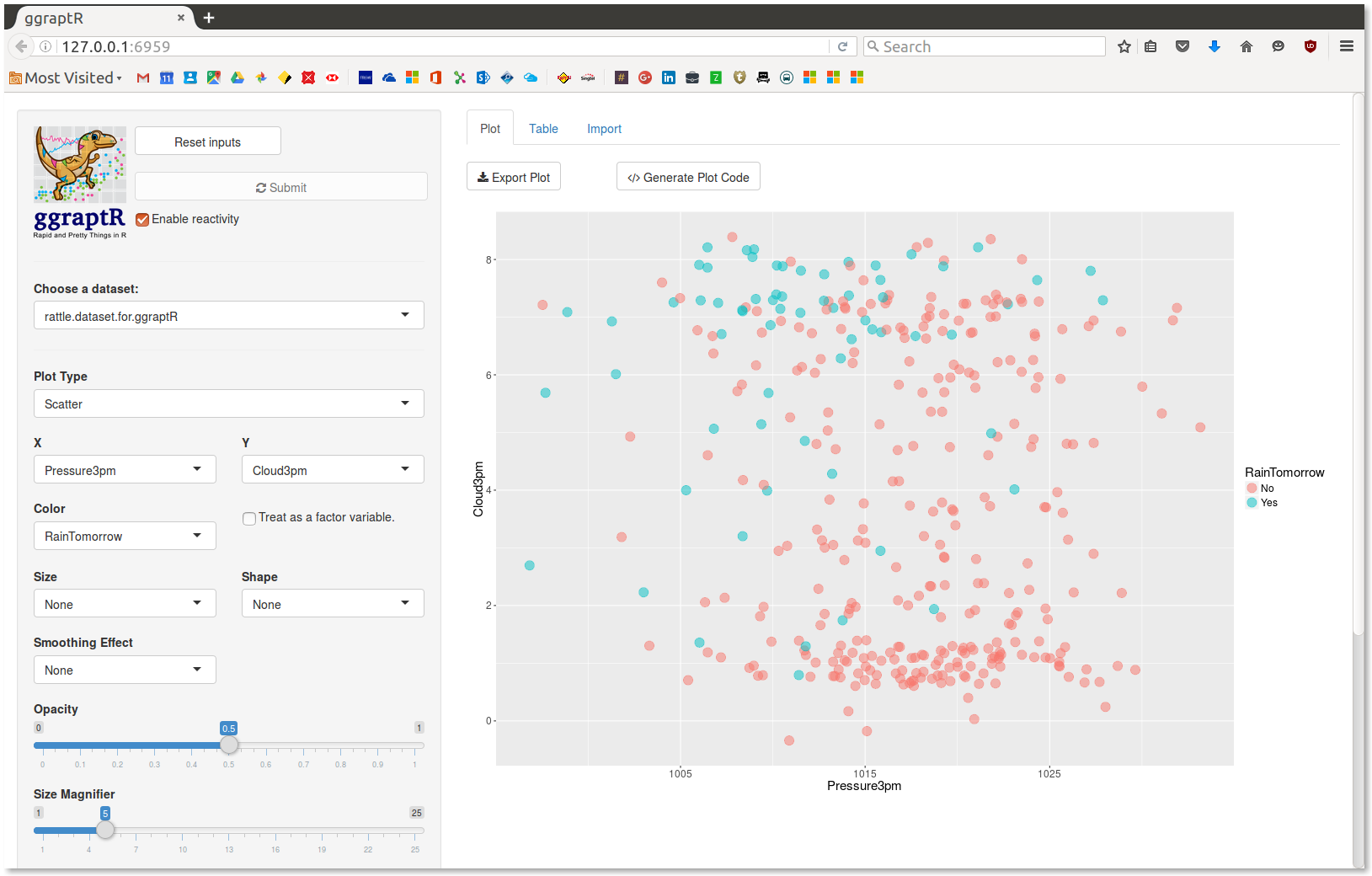
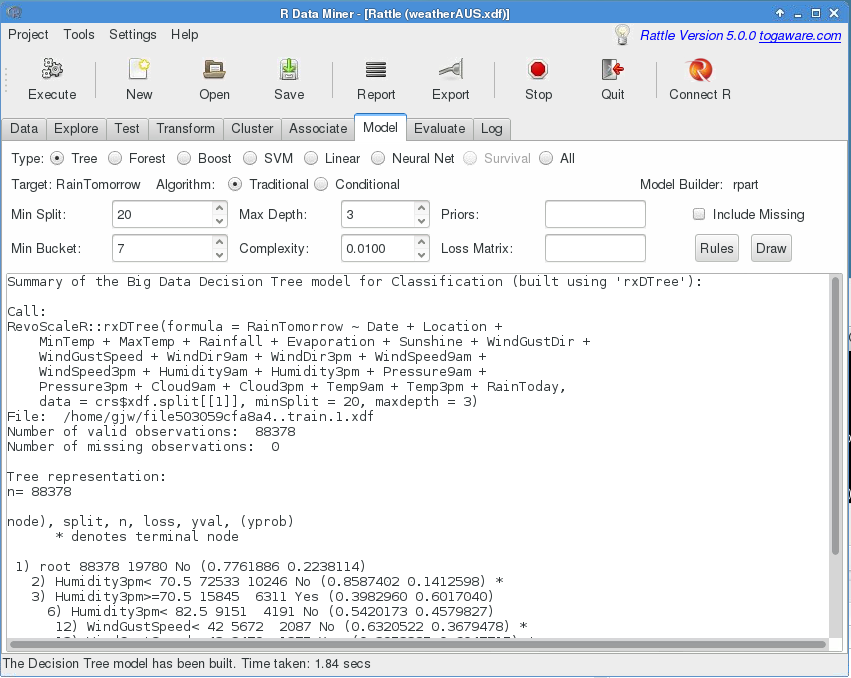
 Data Scientists have access to a grammar for preparing data (Hadley Wickham’s
Data Scientists have access to a grammar for preparing data (Hadley Wickham’s  http://aka.ms/data-science-for-beginners-1
http://aka.ms/data-science-for-beginners-1
Recent Comments